
By Junko Yoshida
What’s at stake:
Everyone loves talking about Edge AI, but without mentioning the persistent gap between the AI and embedded worlds. Edge AI designers are caught in a never-ending cycle of ‘optimization’, pressed to fit neural network models and achieve acceptable accuracy on their hardware. They are desperate for tools to lighten their load. At stake is the scaling of edge AI deployment.
Edge AI today stands at “this uncomfortable junction,” said Evan Petridis, CEO at Eta Compute, in a recent interview with the Ojo-Yoshida Report. Edge AI straddles two domains – machine learning (ML) and embedded. These two distinctly different fields share neither the same language nor design philosophies.
The most obvious gap lies between the speed of tech and product development. Machine learning is moving faster than anything that ordinary hardware designers have ever seen before. On the other hand, the embedded world, where silicon evolves over time, maintains a much more stable, conservative rate of product development.
Differences in design philosophies in ML and Embedded worlds result in ‘a cultural clash, a domain knowledge clash, and development cycle clash.’ – Evan Petridis
Most disconcerting to the embedded community is a big difference in the way two domain experts perceive their design and engineering rigors.
Neural network models developed by data scientists are all statistical. “So, when they can get a model working right, 92 percent of the time, for example, they think they’re winning,” said Petridis. In the traditional embedded world, however, “if you make a mistake and you ship something that doesn’t work 100 percent of the time, you’ve got a massive economic problem … the operational problem is enormous.”
The result is “a cultural clash, a domain knowledge clash, and development cycle clash,” said Petridis. He sees this clash as, potentially, “a huge drag on the deployment of edge AI products.”
Aptos
This week, Eta Compute is rolling out a cloud-based software platform called Aptos, that marks yet another pivot in the company’s business model. Eta Compute started as an AI chip startup in 2015, then became a software IP vendor in late 2020. Now it’s a software-as-a-service (SaaS) platform company.

Evan Petridis
CEO, Eta Compute
Eta Compute’s transformation reflects the teething pains of a still infant edge AI market, and the struggle among many AI hardware startups to find the point where they can finally generate revenue.
Eta Compute explains, “Aptos, a new web-based platform, brings an understanding of the embedded system domain, including the selected chip’s software and silicon AI capabilities and limitations.” The company claims that its web-based tool chain “can streamline the full process cycle of model development, deployment and management for edge machine learning.”
Petridis summed up: “We wanted to build a tool that sits right at the intersection of the embedded and machine learning worlds.”
Eta Compute, however, isn’t the first to develop tools designed to bridge the embedded and AI domains. Edge Impulse founded in 2019 claims that its tool set is “making the process of building, deploying, and scaling embedded ML applications easier and faster.”
While Edge Impulse is more focused on “the top of the funnel” by making it easy for hardware companies “to get started,” Petridis believes Eta Compute’s Aptos will address system designers’ need to dig deeper and develop “production-worthy [edge AI] models.”
Edge AI market landscape
The potential market for either company’s tools appears large because edge AI is a segment where everyone is looking for a big win and fast growth. Certainly, AI accelerator startups and AI inference SoC designers are banking on the edge for a meaningful share in an embedded market where Nvidia has yet to dominate as it does in data centers.
Traditional MCU companies including STMicroelectronics, Renesas and NXP Semiconductors are also working to fold AI into their product portfolios.
Silicon Labs, for example, announced Tuesday an embedded IoT platform called Series 3 with built-in AI/ML engines. With more memory and compute, “we are talking about 100 x step up from where we are today in machine learning capabilities, or vector compute,” said Silicon Labs’ CTO Daniel Cooley.
Silicon Labs’ classic MCUs, built over the last 15 years, have been completely “rethought,” said Cooley, “with the idea these MCUs are connected from day one and they will bring more compute for machine earning.” He predicted that machine learning is going to “get much more interesting in embedded … the way it already has in data centers, mobile and automotive.” Notwithstanding all this outspoken enthusiasm, the actual rate of Edge AI projects going into production is dismally low.
The deployment delay [in edge AI] has plagued not just Eta Compute but all AI chip companies.
Eta Compute’s own experience on the edge AI market taught the company that despite a lot of experiments, prototypes and proofs of concept, edge AI products simply weren’t getting deployed in volume. Well before Petridis signed on, this was Eta Compute’s big problem, despite having a heterogeneous multi-core SoC optimized for ultra-low power AIoT applications.
The deployment delay has plagued not just Eta Compute but all AI chip companies.
Root cause of scaling issues
IDC blamed the scaling problem on issues such as “costs (i.e., hardware accelerators and compute resources), lack of skilled personnel, lack of machine learning operations tools and technologies, lack of adequate volume and quality of data, and trust and governance issues.”
Our interviews reveal that for edge AI developers, basic scaling problems boil down to three factors: the need to hand-craft AI models to achieve accuracy, constant looping back and forth between data scientists and hardware designers, and — like IoT — the fragmented nature of edge-AI applications.
Although often equipped with their own compilers, AI chip companies face difficulties with machinelearning optimization. To preserve functionality, a compiler typically lowers representation – from Ccode, for example, to assembly code, or from behavioral RTL to structural RTL.
But for ML optimization, it isn’t compilers that would complete the job, because “you are literally deleting stuff,” explained Steve Roddy, CMO of Quacric, a machine-learning inference IP company. “The tool chain is effectively telling the data scientists, hey, you have a lot of extra stuff in your baggage that you really don’t need.” Roddy compared this dilemma to showing up at an airport with overweight luggage, although bookedon an ultra-cheap airline.
The tool chain is effectively telling the data scientists, hey, you have a lot of extra stuff in your baggage that you really don’t need – Steve Roddy
Because everything must fit into a carry-on, Roddy said, “I open up your bag and start throwing all your clothes out.”
This is effectively what happens when a data scientist builds an immensely complex neural network model. The task of pruning, sparsity or quantization in ML is “very different from what a standard compiler does.”
But whose job is it to take the clothes out of my suitcase?
Usually, Roddy explained, it’s the embedded person, together with the data scientist. Some companies have “data engineers” or “ML engineers” specifically assigned to bridge the gaps.
Petridis likes the luggage analogy.
But he added that ML optimization involves parameters beyond volume reduction that could reshape the model. “The multi-dimensional nature of ML could turn your bag into an extremely strange shape – even like a star shaped bag.”
Consider a particular neural network operation, said Petridis. “You can run it on the Arm core, or if you’ve got an accelerator and NPU, that might help run it 20 times or 50 times faster. But that is not as flexible as a general-purpose CPU.”
Given the many variables in hardware and software performance, optimization becomes “starshaped,” said Petridis. He noted that humans typically have trouble tracking all the variables in craft
optimization. There are “a handful of people, often in chip companies, who have grown up by studying a particular architecture, and have developed a certain set of heuristics as to how you map things out.” That sort of optimization might work for a certain project, but that’s a recipe for disaster when it sends AI chip companies questing after only a specific edge AI project that don’t scale.

With Aptos, Eta Compute eliminates human hand-crafting in data science, neural network models and complex mapping. It applies machine learning to do discovery on chip performance, profile chips and abstract the hardware, Petrides explained.
When he joined Eta Compute in 2021, “We reshaped the company around this proposition of building the right kind of software infrastructure” to support edge AI. No longer a silicon company, Eta Compute strengthened its machine-learning engineering – putting 60 percent of its experts into machine learning and a third into embedded systems, the CEO explained.
Winning the trust of embedded engineers
Eta Compute has designed Aptos to collapse the back-and-forth optimization process into a single step.
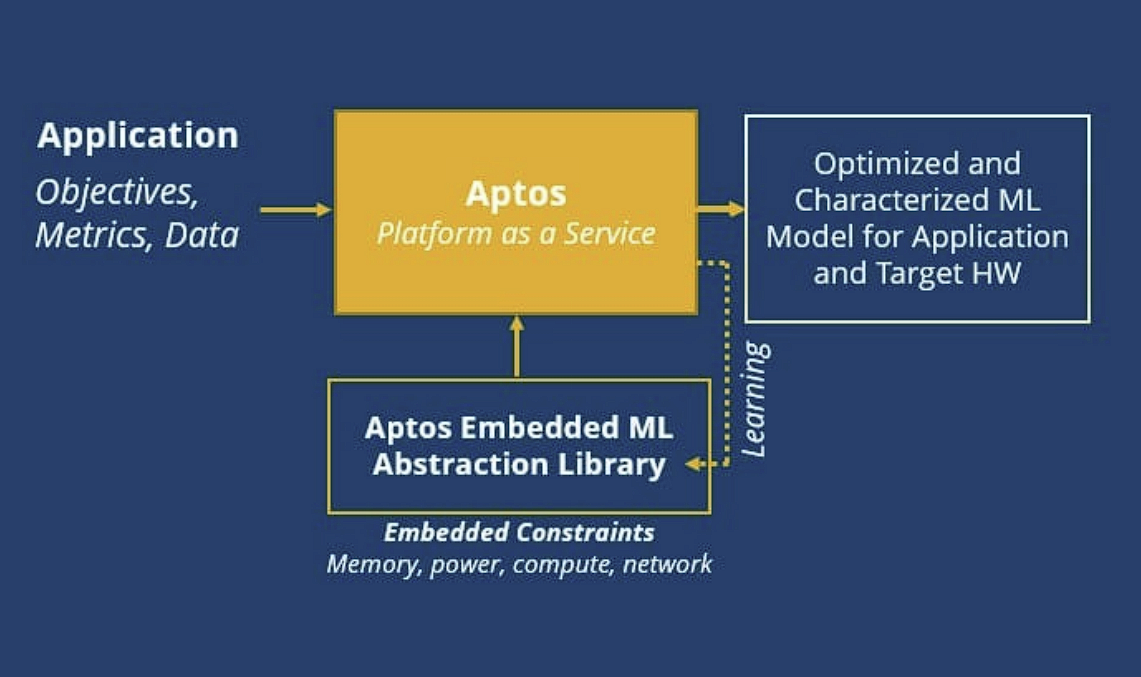
“We do that by abstracting the hardware,” said Petridis. “We make it accurate enough – this is not an estimate – so that embedded engineers can believe it.” At the end, Aptos offers a model, for example, that achieves 90% accuracy on a particular chip, running in 17 milliseconds, using 1.1 millijoules.
“That’s not an estimate or a guess, or an approximation,” stressed Petridis. “That’s measured values. So, if you take that model and integrate that into your software model and run it on your system, you will get the exact same result.”
In essence, Eta Compute claims that Aptos can extract maximum capacity from any architecture currently used by an embedded AI system. Petridis said, “It’s no magic, because the way we do it is to use the vendor’s tools – deep down inside their compiler – because the compiler wants to distribute tasks in a certain way.”
Aptos, rolling out this week, is still in beta, with a handful of people in its early access program, according to the CEO.
Bottom line:
The divide between ML and embedded communities is wide and deep. A growing number of vendors, including Eta Compute and Edge Impulse, contend that an inadequate software infrastructure is hampering potentially explosive growth in commercial edge-AI products.
Junko Yoshida is the editor in chief of The Ojo-Yoshida Report. She can be reached at junko@ojoyoshidareport.com.
Copyright permission/reprint service of a full Ojo-Yoshida Report.